Einführung
Wenn man so einige Sensoren verbaut, kommen mit der Zeit einige Daten zusammen. Dies können Temparaturdaten, Verbrauchsdaten oder auch andere sein. Bislang habe ich diese in eine MariaSQL Datenbank geschrieben und über eine JavaScript Bibliothek von amCharts visualisiert. Die amCharts Bibliothek ist recht umfangreich und bietet eine Vielzahl von Charts und die Einbettung in HTML mit der entsprechenden XML Anbindung ist relativ schnell erledigt.
Nun habe ich seit längerer Zeit mit dem Gedanken gespielt, diese TSD (Time Series Data) in eine andere Datenbank (TSDB) zu schreiben. Ich hatte InfluxDB, RRDTool und Graphite ins Auge gefasst und mich erstmal mit Graphite beschäftigt.
Bei Graphite ist es erstmal wichtig, die Grundstruktur der Komponenten zu verstehen.
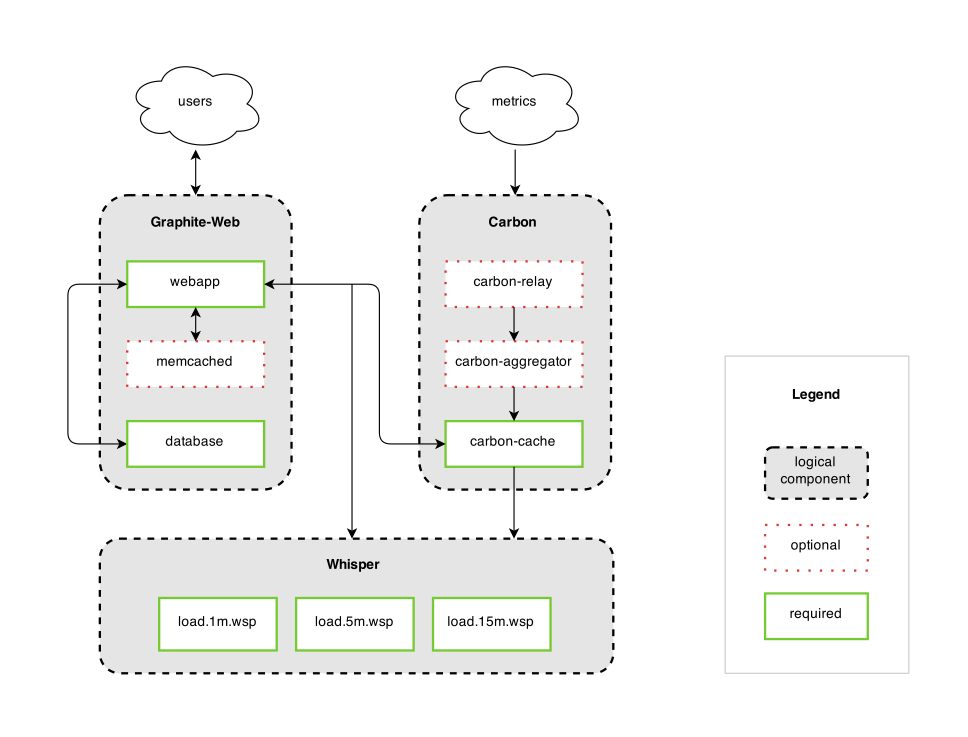
- Carbon – Schnittstelle zum speichern von Time Series Daten (TSD) in der Datenbank
- Whisper – Einfache, file basierende, Datenbank
- Graphite-Web – User Interface & API für das Erstellen von Graphen und Übersichten (Dashboards)
Problem/Mission Statement
In der Testinstallation geht es darum, die folgenden Dinge umzusetzen.
- Installation von Graphite mit Hilfe eines Docker Images.
- Einsammeln von Stromverbrauchsdaten über einen IR Zähler, welcher über Node-RED abgefragt und über Carbon an die Whisper DB übermittelt wird.
- Grundlegende Reports mit Hilfe der Webapp erstellen
Implementierung
Installation von Graphite/Carbon als Docker Image
Die Installation des Docker Images ist mit Hilfe der Beschreibung in der Dokumentation relativ einfach umzusetzen. Ich nutzte das Docker Image: https://hub.docker.com/r/graphiteapp/graphite-statsd/
docker run -d \ --name graphite \ --restart=always \ -p 80:80 \ -p 2003-2004:2003-2004 \ -p 2023-2024:2023-2024 \ -p 8125:8125/udp \ -p 8126:8126 \ graphiteapp/graphite-statsd
Wie oben zu sehen ist, werden hier eine paar Ports gemappt. Für meinen ersten Test werde ich PlainText Daten an den Carbon Receiver übertragen und dafür ist der TCP Port 2003 gemappt.
Nach etwas Suchen in der Node-RED Library habe ich einen Graphite Node gefunden, welcher für das Speichern das Daten in der Datenbank verantwortlich ist.
Problem: Node-RED Graphite Node kann nur UDP
Ich habe relativ früh festgestellt, das der ausgewählte NodeRed Flow für die Anbindung der Carbon Komponenten (https://flows.nodered.org/node/node-red-contrib-graphite) nur für eine UDP Kommunikation geschrieben wurde. Nun hätte ich den Code des Flows anpassen können, habe mich aber dazu entschieden den Carbon Port von TCP 2003 auf UDP 2003 zu ändern.
Lösung:
- Umstellung Port in der Carbon Config
- Ist hier gut beschrieben.
- In der Datei /opt/graphite/conf/carbon.conf des Containers den Wert auf ENABLE_UDP_LISTENER = True setzen.
- Umstellung Port Mapping Docker Container von 2003-2004 auf UDP
docker run -d \ --name graphite \ --restart=always \ -p 80:80 \ -p 2003-2004:2003-2004/udp \ -p 2023-2024:2023-2024 \ -p 8125:8125/udp \ -p 8126:8126 \ graphiteapp/graphite-statsd
Testen der Installation
Nach der Installation kann mit einem einfachen NetCat Kommando getestet werden, ob Carbon auch Daten empfängt. Der unten aufgeführte Befehl schickt einen metric path „local.random.diceroll“ mit einem metric value „4“ und einem metric timestamp „%s“ an den Port. Siehe auch hier.
echo "local.random.diceroll 4 `date +%s`" | nc -u 127.0.0.1 2003
Achtung: Wenn der Port oben nicht von TCP auf UDP umgestellt wurde, dann muss -u auf dem nc statement entfernt werden, weil die Option -u netcat in den UDP Modus schaltet. Wenn netcat den Port nicht sofort schließt, einfach über CTRL-C beenden.
Über die webapp kann man dann sehen, ob die Daten angekommen sind. Einfach mit einem Browser auf die IP des Servers gehen und auf der linken Seite im Menü metrics aufklappen. Hier sollte dann zu erst local und darunter random zu sehen sein. Wenn man dann noch auf den Wert Diceroll klickt, wird dieser rechts in dem Graphen dargestellt.
Wenn jetzt keine Graphen zu sehen sind, liegt dies meist an einige Darstellungsoptionen die noch angepast werden müssen wie z.B. die Zeitzone auf „Europe/Berlin“.
Verarbeitung der Verbrauchsdaten
Wie in meinem früheren Post bereits dargestellt, sammle ich die Verbrauchsdaten des Stromzählers über einen Raspberry ein und schicke diese über ein MQTT Telegram an meinen Server. Hier müssen die Daten nun verarbeitet und in die Graphite/Whisper Datenbank geschrieben werden.
Folgendes ist zu tun:
- Definition des Namensschemas für die Daten in der Whisper Datenbank
- Konfiguration der Whisper Datenbank im Bereich <…>
Naming Schema
Die Entwicklung eines Schemas für die Benennung der Daten ist relativ wichtig, weil sich die Strukturierung der Daten z.B. in der Graphite WebApp daran orientiert. Zudem sollte ein einheitliches und strukturiertes Schema auch die Übersichtlichkeit sicherstellen.
Da ich recht viele Daten über verschiedene Sensoren erfassen, habe ich mir für die Energieverbrauchsdaten das folgende Schema überlegt.
- Consumption.Elecricity.MainMeterTotal // Speicherung des Zählerstands
- Consumption.Elecricity.MainMeterDiff // Speicherung des Vertrauchs in 5 Minuten
Das bedeutet, wenn ich die Daten über das Plan-Text Protokoll erfassen möchte, muss der Node-RED Node folgendermaßen konfiguriert werden.
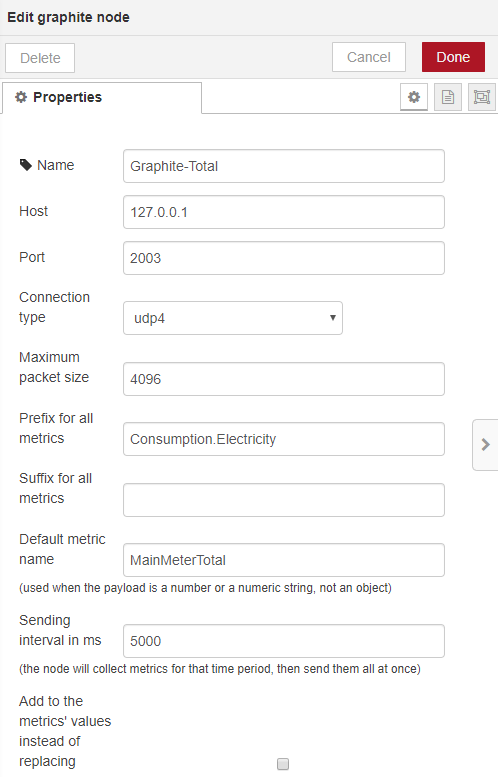
So wird dann der Gesamtverbrauch gespeichert. Nun möchte ich aber auch den Verbrauch in einer definierten Periode (5 Min.) in der Datenbank abspeichern. Leider gibt mein Stromzähler diese OBIS Kennziffer nicht her, sodass ich diese im Node-RED errechnen muss. Ich habe dies über einen Function Node (Extract-Data) gelöst mit dem folgenden Code:
var delta = "0.2333";
var oldvalue = parseFloat(flow.get ('oldvalue'));
msg.oldvalue = oldvalue;
var newvalue = parseFloat(msg.payload);
msg.newvalue = newvalue;
delta = newvalue - oldvalue;
flow.set ('oldvalue', newvalue);
msg.payload = fixedNum = parseFloat(delta).toFixed( 5 );
return msg;
Es geht darum die Differenz zwischen den beiden Werten zu ermitteln, die im Zeitraum von 5 Minuten eintreffen. Dabei ist wichtig, dass der alte Werte im Node-RED gespeichert wird. Hierzu hat mir die folgenden Anleitung geholfen.
Parallel zur Graphite Datenbank habe ich die Daten (Gesamtverbrauch und Verbrauch innerhalb von 5 Minuten) noch ein zwei Node-RED Charts geschrieben.
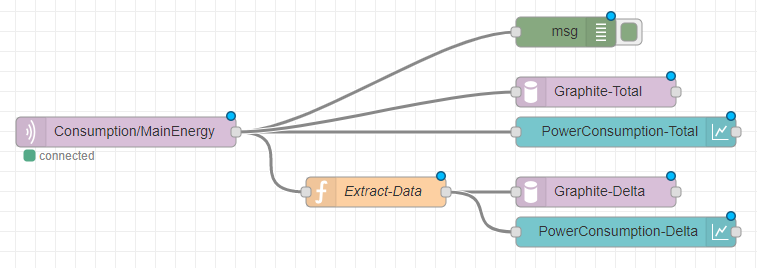
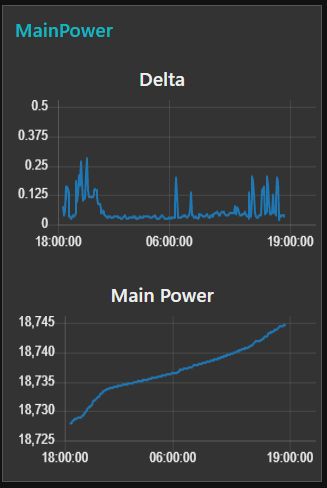
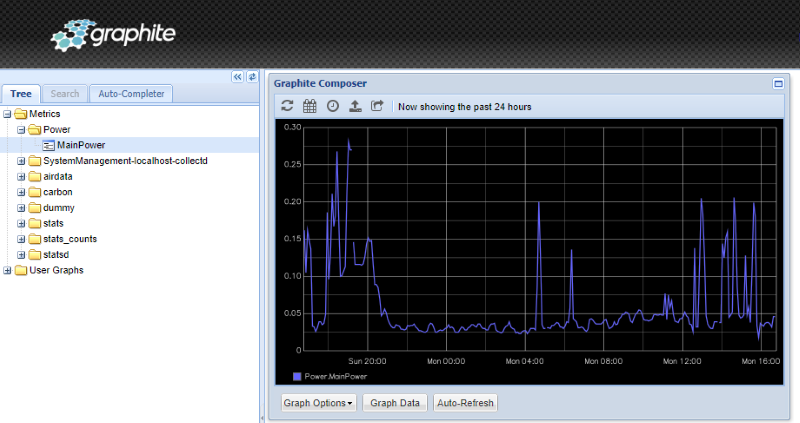
Graphite Browser
Auf der graphite Web-Oberfläche sieht das Ganze dann folgermaßen aus.
Data Retention
Nach der Erstellung der Namenshierarchie ist es wichtig, die Aufbewahrungszeit (Retention time) für die Daten festzulegen. Whisper ist eine dateibasierte Datenbank mit einer festen Größe. Das bedeutet, dass beim Eintreffen des ersten Datums die Aufbewarhrungszeiten für die Daten bereits konfiguriert sein müssen damit die Datei mit der festen Größe angelegt werden kann.
Ein schönes Artikel darüber befindet sich hier.
Die Konfiguration für die Aufbewahrung wird in der Datei storage-schemas.conf erledigt. Diese liegt, zumindest bei meinem Docker Container, unter /opt/graphite/conf/. Die Dokumentation dazu ist hier zu finden.
Eine Regeln besteht dabei aus drei Zeilen.
- Ein Name für die Regel in eckigen Klammern
- Eine python regex nach dem Parameter pattern. Als Einführung hilft ggf. das hier.
- Die Definition der Aufbewahrung nach dem Parameter retentions.
Wichtig ist, dass die Config von oben nach unten abgearbeitet wird. Das heißt, wenn über die Pattern expression in Treffer vorliegt, werden die entsprechenden Retentions gezogen und die Datei wird nicht weiter nach Treffern durchsucht.
Wird die Retention nicht verändert, und die default Konfiguration genommen, dann sieht diese folgendermaßen aus.
[default_1min_for_1day] pattern = .* retentions = 10s:6h,1m:6d,10m:1800d
Die Config ist folgendermaßen zu lesen:
- pattern = .* – Ist so eine Art „catch all“ und sollte am Ende der Datei stehen. Alles was nicht durch ein pattern erkannt wurde, wird hier mit den default retentions versehen.
- retentions = 10s:6h; 5m:30d, 1h:3y
- Hier kommen Daten alle 10 Sekunden rein. Diese werden in dieser Auflösung für 6 Stunden gespeichert.
- Nach 6 Stunden werden diese Daten auf den Durchschnittswert, oder was auch immer als aggregation schema konfiguriert wurde, von 5 Minuten verdichtet und 30 Tage gehalten.
- Nach 30 Tagen werden die Daten den Durchschnittswert, oder was auch immer als aggregation schema konfiguriert wurde, von einer Stunde verdichtet und 3 Jahre aufbewahrt.
Wenn man also zuersteinmal Daten über Carbon an die Whisper Datenbank gibt und die Retensions nicht zu der Frequenz der einkommenden Daten passt, wundert man sich u.U. das Lücken in den Daten enstehen.
Debugging
Die Konfiguration der Retentions Schemas mit den Python RegExs ist für ungeübte, also mich, nicht so einfach. Es musste daher schnell eine Debugging Methode her. Das „matching“ der einkommenden Daten gegen die Retention Config kann in der Datei carbon.log mitgeschrieben werden. Damit dies geschieht, muss der Parameter „LOG_CREATES = TRUE“ in der Konfigurationsdatei /opt/graphite/conf/carbon.conf gesetzt sein.
# By default, carbon-cache will log every whisper update and cache hit. # This can be excessive and degrade performance if logging on the same # volume as the whisper data is stored. LOG_UPDATES = False LOG_CREATES = True LOG_CACHE_HITS = False LOG_CACHE_QUEUE_SORTS = False
Nun nach dem Neustart mit nc einen Wert an Carbon schicken. Achtung: Bitte auf die die Backticks vor und nach dem date achten.
echo "local.carbonlogtest 42 `date +%s`" | nc -u 127.0.0.1 2003
… und dann mit einerm tail die entsprechenden [creates] ausgeben lassen und man kann das matching (hier zum Schema „default_1min_for_1day“) sehr gut sehen.
tail -f carbon.log | grep creates ::[creates] new metric local.carbonlogtest matched schema default_1min_for_1day ::[creates] new metric local.carbonlogtest matched aggregation schema default_average ::[creates] creating database metric local.carbonlogtest (archive=[(60, 2592000)] xff=0.3 agg=average)
Mit dem Befehl whisper-info.py kann man dann noch die whisper Datei analysieren.
cd /opt/graphite/bin python3 whisper-info.py /opt/graphite/storage/whisper/local/carbonlogtest.wsp aggregationMethod: average maxRetention: 155520000 xFilesFactor: 0.30000001192092896fileSize: 31104028 Archive 0 offset: 28 secondsPerPoint: 60 points: 2592000 retention: 155520000 size: 31104000
Retension Schema für Verbrauchsdaten
Nun habe ich mir überlegt, welche Auflösung und welche Aufbewahrung ich nun für meine Verbrauchsdaten haben möchte. Ich habe jetzt erstmal die 5 Minunten auf 5 Jahre genommen, so dass meine Config in /opt/graphite/conf/storage-schemas.conf jetzt so aussieht.
[Consumption.Electricity] pattern = ^Consumption.Electricity\. retentions = 5m:1800d
Das wurde dann auch gleich erkannt und die beiden Files wurden angelegt.
:: [creates] new metric Consumption.Electricity.MainMeterTotal matched schema Consumption.Electricity :: [creates] new metric Consumption.Electricity.MainMeterTotal matched aggregation schema default_average :: [creates] creating database metric Consumption.Electricity.MainMeterTotal (archive=[(300, 518400)] xff=0.3 agg=average) :: [creates] new metric Consumption.Electricity.MainMeterDiff matched schema Consumption.Electricity :: [creates] new metric Consumption.Electricity.MainMeterDiff matched aggregation schema default_average :: [creates] creating database metric Consumption.Electricity.MainMeterDiff (archive=[(300, 518400)] xff=0.3 agg=average)
Eine weitere einfache Möglichkeit zu prüfen ob Daten in der Datenbank ankommen ist die API Schnittstelle. Hier einfach im Browser folgenden Befehl eingeben und die Daten werden als JSON im Browser dargestellt. Der Hostname muss selbstverständlich angepasst werden.
http://<hostname>:8080/render?target=Consumption.Electricity.MainMeterDiff&format=json&from=-2h
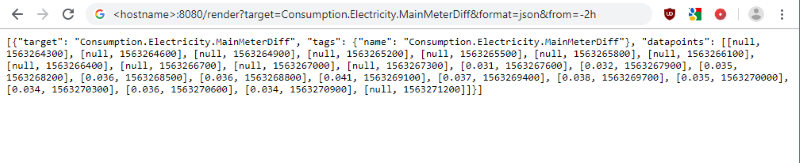
Ein weiteres Debug-Tool welches ich empfehlen kann, ist das Epoch & Unix Timestamp Conversion Tool. Die Zeiten in der Whisper DB werden als Unix Epoch Time gespeichert und bei der Kontrolle der Daten kann es sinnvoll sein, diese mal in „human-readable“ format umzuwandeln.
Daten löschen
Wenn man nun beim ausprobieren ein paar mehr Datenpunkte geschaffen hat als man braucht, können diese schnell auf Fileeben gelöscht werden. Dazu einfach den entsprechenden Ordner oder Datei unterhalb von /opt/graphite/storage/whisper löschen.
Next Steps
Als nächstes möchte ich die Daten natürlich etwas hübscher darstellen. Zum Einen würde ich gerne die neue amCharts Library ausprobieren und ob die Datenhaltung mit Graphite/Whisper jetzt signifikante Vorteile ggü. der MariaDB Datenhaltung hat und zum anderen möchte ich auch die Möglichkeiten von Grafana testen.
Es bleibt interessant…